『The Neuro-Symbolic Concept Learner Interpreting Scenes Words and Sentences From Natural Supervision』阅读笔记
- Learns visual concepts, words, and semantic parsing of sentences without explicit supervision on any of them, but just by looking at images and reading paired questions and answers
- 符号主义和连接主义的结合。符号主义体现在程序执行器program execution:定义了DSL,学习到显示的嵌套任务,每个在执行任务时,根据定义执行每个DSL定义的功能,没有参数需要学习;连接主义体现在视觉感知R-CNN和自然语言处理时的autoencoder模型
- 模型学习到解耦的视觉和语言概念,可以通过组合来泛化到训练集没出现的样本
- 使用paired images, questions, and answers 三元组 来共同训练视觉和语言模块
- 针对这个数据集进行设计的模型,比如在Concept quantization设计时,就对数据集中 shape attribute 中的典型编码构成一个 shape embedding空间;以及设计的DSL(Domain Specific Language)
专有名词
- 视觉推理(visual reasoning) 视觉推理(Visual Reasoning)神经网络也可以有逻辑
ABSTRACT
我们提出了神经符号概念学习器(NS-CL),该模型可以学习视觉概念,单词和句子的语义解析,而无需对它们中的任何一个进行监督。相反,我们的模型只是通过查看图像并阅读配对的问题和答案来学习。我们的模型建立了一个基于对象的场景表示并将句子翻译成可执行的符号程序。为了简化两个模块的学习,我们使用了神经符号推理模块,该模块在潜在场景表示上执行这些程序。类似于人类概念学习,感知模块基于所引用对象的语言描述来学习视觉概念。同时,学习到的视觉概念有助于学习新单词和解析新句子。我们使用课程学习curriculum learning 来指导对图像和语言的巨大组成空间的搜索。大量实验证明了我们的模型在学习视觉概念,单词表示和句子的语义解析方面的准确性和效率。此外,我们的方法允许轻松地将其推广到新的对象属性,组成,语言概念,场景和问题,甚至是新的程序域。它还支持包括视觉问题解答和双向图像文本检索在内的应用程序
(利用一种符号化推理过程联结视觉概念、词以及句子的语义分析,根据场景表征来推理答案,且无需对其中任何一种提供显式注释)
1 INTRODUCTION
人类有能力通过共同理解视觉和语言来学习视觉概念(Fazlyet等,2010;Chrupała等,2015; Gauthier等,2018)。考虑图1-I所示的示例。想象一下,一个没有先验颜色知识的人看到了红色和绿色立方体的图像,以及问题和答案。他们可以轻松地识别对象的视觉外观差异(在这种情况下为颜色),并将其与问题和答案中的相应单词对齐(红色和绿色)。可以类似的方式学习其他对象属性(例如形状)。从那里开始,人类能够归纳地学习视觉概念和单词语义之间的对应关系(例如 空间关系和引用表达式,图1-II),并且解构复杂问题的逻辑结合学习的视觉概念(图1-III,另请参见Abend等人(2017))
为此,我们提出了一种 神经符号概念学习器(NS-CL),它可以从图像和问答对中共同学习: 视觉感知、单词、语义语言解析。NS-CL具有三个模块:基于神经的感知模块从场景中提取对象级别的表示,将问题转换为可执行程序的可视化语义解析器以及读取对象的感知表示,对对象的属性/关系进行分类的符号程序执行器,并执行程序以获取一个答案

NS-CL从自然监督natural supervision中学习(即 图像 和 QA对 ),不需要在图像上注释或 用于句子语义注释的程序。相反,类似于人类概念学习,它通过课程学习来学习curriculum learning。NS-CL首先从简单场景(≤3个对象)中的简短问题 (What’s the color of the cylinder) 中学习单个对象的表示/概念开始。通过这样做,它学习了基于对象的概念,例如颜色和形状。然后,NS-CL通过利用这些基于对象的概念 来解释对象引用,从对象引用学习关系概念 (e.g., Is there a box right of a cylinder?). 该模型可迭代地适应更复杂的场景和高度复杂组合的问题
NS-CL的模块化设计实现了可解释,鲁棒和准确的视觉推理 interpretable, robust, and accurate visual reasoning:在CLEVR数据集上实现了最先进的性能(Johnson等,2017a)。更重要的是,它自然地学习了解耦的视觉和语言概念,从而通过组合来泛化到训练集没出现的样本。视觉场景和语义程序。特别是,我们展示了四种形式的概括。首先,与训练集中的场景相比,NS-CL泛化到具有更多对象和更长语义程序的场景。其次,它概括了CLEVR-CoGenT(Johnson et al。,2017a)数据集上演示的新视觉属性组成。第三,它可以快速适应新的视觉概念,例如学习新的颜色。最后,学习到的视觉概念无需任何微调即可转移到新任务,例如图像字幕检索
2 RELATED WORK
我们的模型与视觉和自然语言的联合学习有关。尤其是,有许多论文从描述性语言中学习视觉概念,例如图像说明或视觉基础的问答对 image-captioning or visually-grounded question-answer pair (Kiros等人,2014; Shi等人,2018; Mao等人,2016; Vendrov等人等人, 2016; Ganju等人,2017),场景的密集语言描述dense language descriptions for scenes(Johnson等人,2016),视频字幕(Donahue等人,2015)和视频文本对齐(Zhu等人,2015).
视觉问题解答(VQA)脱颖而出,因为它需要了解视觉内容和语言。最先进的方法通常使用神经注意力 neural attention(Malinowski&Fritz,2014; Chen et al,2015; Yang et al,2016; Xu&Saenko,2016)。除了 question answering 之外,约翰逊(Johnsonet)等。(2017a)提出了CLEVR(VQA)数据集来诊断推理模型 diagnose reasoning mode。CLEVR包含综合的视觉场景和从潜在程序生成的问题。表1将我们的模型与最新的视觉推理模型(Andreas等,2016; Suarez等,2018; Santoro等,2017)沿四个方向进行了比较:视觉特征,语义,推理和要求附加标签。 visual features, semantics, inference, and the requirement of extra labels
对于视觉表示 visual representations,Johnson等人(2017b)将视觉场景编码为程序操作符program operator 的 卷积特征图。 Mascharka等(2018); Hudson&Manning(2018)使用注意力作为中间表示法来透明地执行程序。 最近,Yi等(2018)探索了用于视觉推理的可解释的,基于对象的视觉表示interpretable, object-based visual representation。它的表现很好,但是在训练过程中需要 有注释的场景 fully-annotated scenes。我们的模型还采用了基于对象的视觉表示,但是该表示只能在自然监督下学习(问题和答案)
Anderson et al. (2018) 也提出将图像表示为卷积对象特征convolutional object features的集合,并在VQA上获得了实质性的改进。他们的模型使用神经网络编码问题并通过 question-conditioned attention over the object features 来回答问题。相反,NS-CL将问题输入解析到程序中,并在对象特征上执行它们以获得答案。这使得推理过程可以解释,and supports combinatorial generalization over quantities (e.g., counting objects)。我们的模型还学习一般的视觉概念及其与语言符号表示的关联。然后,可以将这些学习到的概念明确地解释并部署到其他视觉语言应用程序中,例如图像标题检索
用于视觉推理的语义语句解析有两种方法:作为条件神经操作的隐式程序(例如,条件卷积和双重注意)(Perez等人,2018; Hudson&Manning,2018)和显式程序作为序列象征性代币的交易(Andreaset等,2016; Johnson等,2017b; Mascharka等,2018)。作为代表,Andreas等人(2016年)基于用于回答问题的程序构建了模块化和结构化的神经体系结构,显式程序具有更好的可解释性,但通常需要额外的监督,例如用于训练的真实的程序注释。这限制了它们的应用。我们建议使用视觉基础作为远程监督, to parse questions in natural languages into explicit programs, with zero program annotations。给定问题的 semantic parsing,Yi等人。(2018)提出了一个纯粹的符号执行器 symbolic executor 来推理逻辑空间中的答案。与他们的相比,我们为VQA提出了一个we propose a quasi-symbolic executor for VQA
我们的工作还涉及使用神经网络为视觉场景学习可解释和解耦的表示形式。Kulkarni等提出了卷积逆图形网络,用于学习和推断人脸姿势。(Yang et al2015年)从图像中学到了椅子姿势的 解耦表示disentangled representation。Wu等(2017)提出了神经场景去渲染框架,作为任何渲染过程的逆过程。Siddharth等; (2017)希金斯等。(2018)使用深度生成模型学习 解耦的表示形式。相反,我们提出了一种通过语言联合推理 joint reasoning的替代表示学习方法
3 NEURO-SYMBOLIC CONCEPT LEARNER
我们介绍了我们的神经符号概念学习器 neuro-symbolic concept learner,它使用符号推理过程来桥接视觉概念,单词和句子的语义解析的学习,而无需显式注释
我们首先使用视觉感知模块visual perception module ,构建基于对象的表示object-based representation for a scene,然后运行语义解析模块将问题semantic parsing module转换为可执行程序。然后我们使用 quasi-symbolic program executor使用这个场景目前所得到的representation来推断答案,我们使用paired images, questions, and answers 三元组 来共同训练视觉和语言模块

用 symbolic, functional 的 modules 增加可解释性,可组合性和可泛化性
给定输入图像:(1) the visual perception module detects objects in the scene and extracts a deep, latent representation for each of them. (2) 语义分析模块负责将输入的问题解析为一个程序,这个程序是由该问题的领域特定语言(Domain Specific Language, DSL)中的操作定义的。(3) quasi-symbolic program executor根据视觉产生的场景描述和问题解析生成的可执行程序来回答问题 (4) 可微分,可以基于现有的优化器优化
3.1 MODEL DETAILS
视觉感知模块(Visual perception)
对于视觉感知,研究人员使用了预训练的Mask R-CNN 作为 proposal generator 生成 object proposals。然后,由于需要获取到Object在场景中的位置信息,则将 The bounding box for each single object paired with the original image 输入到Res-Net-34,到的是不同的object feature. 一张图有多少个object 就有多少个object feature。bounding box 通过 RoI Align提取object区域内的特征 和 original image 提供基于图像的 context 特征信息(对于推断相关属性(例如大小或空间位置)必不可少)。 concatenate 两个特征 to represent each object
视觉概念的量化(Concept quantization)
进行视觉推理需要获取每个对象的属性(例如颜色、形状等)。每一个属性类别(Attribute,例如:颜色)可以有多个视觉概念(Concept,例如:红色、绿色)的取值。
In NS-CL, 视觉属性被实现为 neural operators (每个operator代表一个属性的投影方程)。operator 接收 Object 的 表示向量,将其映射到特定属性的编码空间(attribute specific embedding space)中的向量,并且与视觉概念在嵌入空间中的向量计算距离(论文中metric采用 cosine distances $<·,·>$),sigmoid输出[0,1]范围内的概率值,以此确定 object 在 object attribute 的 object concept 值

同样地,将 a pair of objects 间的关系分类成不同的 relational concepts (e.g.,Left) ,除了分类,我们将两个对象的视觉表示串联,以形成它们之间关系的表示
DSL和语义分析(DSL and semantic parsing)
概括:语义分析模块负责将输入的问题解析为一个程序,这个程序是由 对领域 VQA 的特定语言(Domain Specific Language, DSL)中的操作定义的 一个有层次结构的程序。
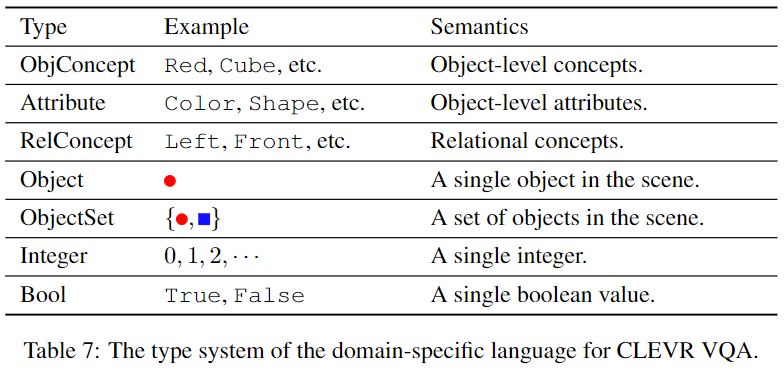
DSL 中包含的基本操作 for visual reasoning 有:such as filtering out objects with certain concepts or query the attribute of an object。 为了模块化,基本操作模块共享相同的输入和输出接口:
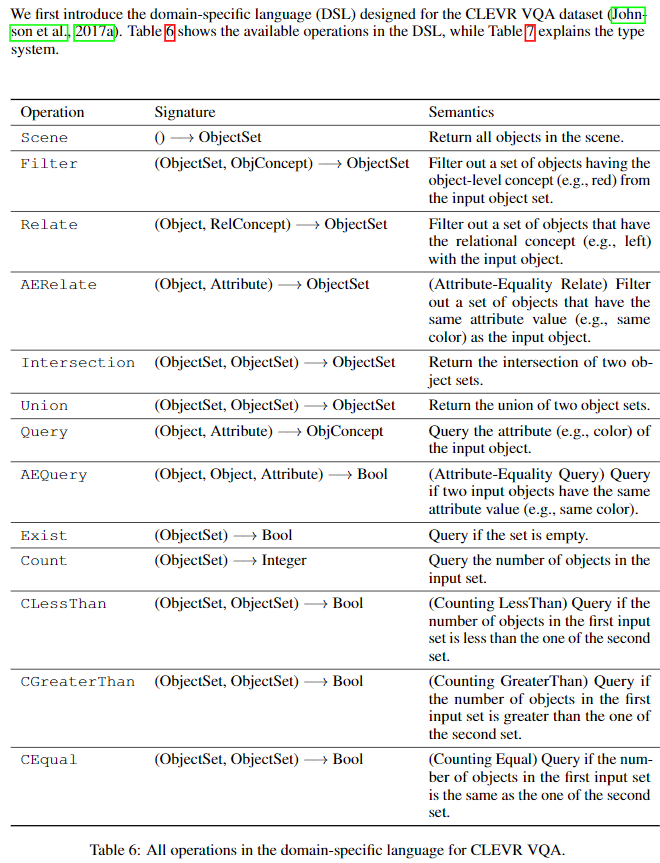
有的操作对象是 Object 而不是 objectSet,这里有个Unique 的概念
具体实现上,该模块将 顺序句子转化成 树状结构。首先a bidirectional GRU 'IEncoder'负责将自然语言编码成一个固定维度的向量;随后decoder based on GRU cells 'OpDecoder'determines the operation tokens; ConceptDecoder负责产生操作需要的Concept或Attribute参数;对于operation tokens输入为 non-concept input ,OEncoder_i将当前的state $f$ transform into 两个 sub-state $f_1, f_2$ 成为两个branch,如此递归执行。算法流程如下:

$c\{i\}$是 natural language 问句中出现过的所有Concept和Attribute的合集
具体实现见文章的 附录B
程序执行器
为了让最终结果(即程序执行器最终给出的答案)相对于模型参数(感知模块的参数、概念编码、Attribute操作符)可导,两者均采用基于概率的表示方法:输入是Object 类型变量的Representations,输出一个mask over object,mask长度为object数量,mask每个位置数值代表概率

详见 appendix C
3.2 TRAINING PARADIGM 训练方法
优化目标
训练目标是找到最优参数 $\Theta_V、\Theta_S$ $\Theta_V$ 是感知模块 Perception Module的参数(包括ResNet-34的参数,属性操作符的参数,concept embeddings),$ \Theta_S$ 是语义分析模块Visually-Grounded Semantic Parser的参数,使得回答出正确答案的概率最大:

如何优化这个目标函数?

课程学习(Curriculum Learning)的训练方法,即先让模型学习简单的例子,然后慢慢扩展到复杂的场景

4 EXPERIMENTS
4.1 VISUAL CONCEPT LEARNING
Classification
在 CLEVR 拆分的验证集中 evaluate the concept quantization

Count
SOTA方法无法提供单个对象的可解释表示(Johnson等,2017a; Hudson&Manning,2018; Mascharka等,2018)。为评估此类模型学习的视觉概念,我们生成了一个综合问题集。诊断问题集包含以下形式的简单问题:“有多少个红色物体?”。我们评估了CLEVR数据集中出现的所有概念的性能。
实验说明基于对象的视觉表示和符号推理有助于解释视觉概念。
4.2 DATA-EFFICIENT AND INTERPRETABLE VISUAL REASONING
表4总结了CLEVR验证拆分的结果。我们的模型使用零程序注释(包括MAC(Hudson&Manning,2018)和FiLM(Perez et al,2018))在所有基线中实现了最先进的性能。我们的模型通过强大的基线TbD-Nets(Mascharka et al。,2018)达到了可比的性能,它的语义解析器使用CLEVR中的700K程序进行了训练(我们需要0训练数目)。Yi等人最近的NS-VQA模型(2018)在CLEVR上取得了更好的性能;但是,他们的系统在训练过程中需要带注释的视觉属性和程序 trace,而我们的NS-CL不需要额外的标签
在这里,视觉感知模块在ImageNet上进行了预训练(Deng等,2009)。如果不进行预培训,则概念学习的准确性平均下降0.2%,而QA准确性下降0.5%。同时,NS-CL可以准确地恢复基本的问题程序(准确度> 99.9%)。NS-CL还可以检测到模棱两可或无效的程序并指示异常。有关更多详细信息,请参见附录F。NS-CL也可以应用于其他视觉推理测试平台。我们在Minecraft数据集上的结果请参考附录G.1(Yi等人,2018)。
为了对视觉特征和数据效率进行系统研究,我们实现了基线模型的两个变体:TbD-Object and MAC-Object。受(Anderson等人,2018)的启发,TbD-Object and MAC-Object 代替输入图像,而将a stack of 对象特征作为输入。TbD-Mask 和 MAC-Mask integrate the masks of objects by using them to guide the attention over the images
这源于视觉概念学习和符号推理的完全解耦:如何根据所学概念concept 执行程序指令。
在我们的实验中, TbD-Object and MAC-Object 显示的结果较差。我们将其归因于模型架构的设计,并在附录F.3中进行了详细分析。尽管TbD-Mask和MAC-Mask的性能不比原始产品好,但我们发现using masks to guide attentions speeds up the training
4.3 GENERALIZATION TO NEW ATTRIBUTES AND COMPOSITIONS
Generalizing to new visual compositions.
CLEVR-CoGenT数据集旨在评估模型推广到新视觉组成的能力。它具有 two splits: Split A 仅包含灰色,蓝色,棕色和黄色的立方体,但是包含红色,绿色,紫色和青色的圆柱体;split B 在立方体和圆柱体上施加了相反的颜色约束。如果我们直接在 split A 上学习视觉概念,则它会过度拟合以根据颜色对形状进行分类,从而导致split B 的泛化性很差
我们的解决方案基于将属性视为运算符seeing attributes as operator的想法(感觉这里引入了先验的知识,有哪些attributes,强制学到这些attributes,而直接学习,没有强制学习这些attributes,可能因为attributes的冗余,只需要少量的attributes就能达到好的分类效果使得泛化能力差 )。具体来说,我们在拆分A上联合训练概念嵌入(例如Red,Cube等)以及语义解析器,同时保留经过预训练的冻结属性运算符。当我们学习不同属性的不同表示空间时,我们的模型在A组中的准确性达到98.8%,在 split B 中的准确性达到98.9%
Generalizing to new visual concepts.
我们期望 concept learning 的过程可以逐步进行:学习了7种不同的颜色后,人类可以逐步有效地学习第8种颜色。为此,我们构建了CLEVR数据集的综合拆分,以复制增量概念学习的设置 replicate the setting of incremental concept learning。 Split A 仅包含没有任何紫色对象的图像,而 split B 包含具有至少一个紫色对象的图像。我们先在 split A 上训练了所有模型,并在 split B 中的100张图像上对其进行了微调。我们报告了 split B 的验证集的最终质量检查效果。所有模型都在完整的CLEVR数据集上使用了预训练的语义解析器。
4.4 COMBINATORIAL GENERALIZATION TO NEW SCENES AND QUESTIONS
在小规模场景(仅包含少量对象)和简单问题(仅 single-hop 问题)上学习了视觉概念之后,我们人类可以轻松地将知识推广到更大范围的场景并回答复杂的问题。为了对此进行评估,我们将CLEVR数据集分为四个部分:Split A 仅包含少于6个对象的场景,以及由自然语言问题转换成的 latent programs 深度小于5的问题; Split B 包含少于6个对象的场景,但是有任意问题; Split C 问题包含任意场景,但将程序深度限制为小于5; Split D 包含任意场景和问题。 图6显示了一些说明性示例。

由于VQA基线无法计算一组任意大小的对象,为了进行公平的比较,所有包含“ count”运算超过6个对象的程序都将从该集合中删除。
对于使用 explicit program semantics 的方法,语义解析器在完整数据集上进行预训练并固定。具有隐式程序语义的方法implicit program semantics (Hudson & Manning, 2018) 学习了耦合的表示法以进行感知和推理,因为耦合所以无法简单地将其推广到更复杂的程序中,我们仅使用Split A的训练数据,然后在其他三个split上对泛化能力进行量化。如表5所示,我们的NS-CL可以将大范围场景和更复杂的问题几乎完美地泛化,在质量保证准确性方面,所有基线均优于至少4%。
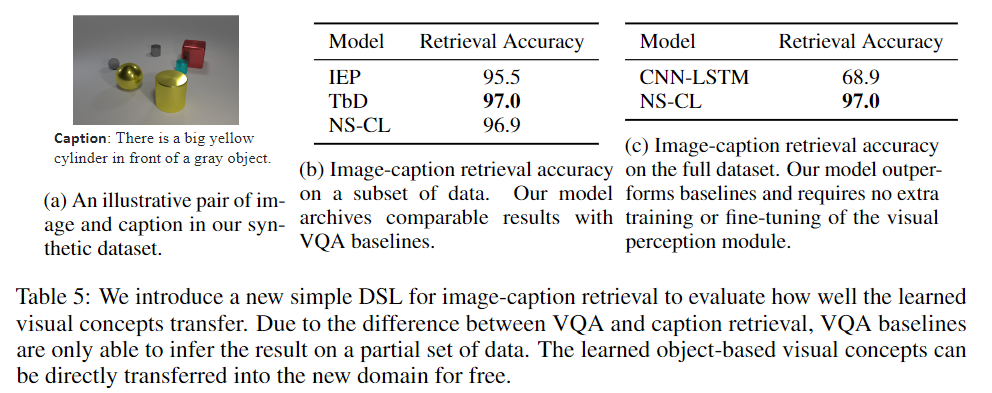
4.5 EXTENDING TO OTHER PROGRAM DOMAIN
学到的视觉概念也可以用于其他领域,例如图像检索image retrieval。通过固定视觉场景,可以将学习到的视觉概念直接转移到新领域With the visual scenes fixed, the learned visual concepts can be directly transferred into the new domain.。我们只需要学习自然语言的语义解析到 新领域的DSL中。
我们建立了用于图像检索的综合数据集synthetic dataset,并采用了基于场景图的图像检索scene graph–based image retrieval (Johnson等,2015)中的DSL。数据集仅包含简单的标签 an $
为了简单起见,我们将检索视为 classifying whether a relational triple exists in the image。无法在CLEVR VQA program domain 上直接实现此功能,因为如果场景中存在多个圆柱体,则诸如“圆柱体的盒子右边是否存在”之类的问题可能会模棱两可。由于视觉表示与特定的DSL 是耦合在一起的,因此在CLEVR QA上训练的基线无法直接应用于此任务。为了与它们进行公平的比较,我们在生成的 image-caption pairs 的子集上在表5b中显示了结果,其中底层程序对对象B的引用没有歧义。针对VQA基线训练了一个单独的语义解析器,which translates captions into a CLEVR QA-compatible program $(e.g.,Exist(Filter(Box, Relate(Right, Filter(Cylinder)))$
4.6 EXTENDING TO NATURAL IMAGES AND LANGUAGE
我们进一步在MS-COCO(Lin等人,2014)图像上进行实验。结果显示在VQS数据集上(Gan等人,2017)。VQS包含来自原始VQA 1.0数据集的图像和问题的子集(Antol等,2015)。VQS数据集中的所有问题都can be visually grounded:每个问题都与多个图像区域相关联,这多个区域都是回答问题的必要条件人,于是都有标注。图7说明了VQS上NS-CL的执行轨迹

附录H中提供了有关NS-CL的其他示例性执行痕迹。除了回答问题以外,NS-CL还可以从数据中有效学习视觉概念。图8显示了学习到的视觉概念的示例,包括对象类别,属性和关系。实验设置和实现的详细信息在附录G.2中。
Indeed, visual question answering requires AI systems to reason about more general concepts such as events or activities (Levin, 1993). We leave the extension of NS-CL along this direction and its application to general VQA datasets (Antol et al., 2015) as future work
5 DISCUSSION ANDFUTUREWORK
reference1
神经符号概念学习器使用人工神经网络技术来从图像中提取特征并将信息构造为符号,然后将准符号程序执行器应用于模型,以基于场景表示(image)来推断问题的答案。
对于视觉感知,研究人员使用了预训练的Mask R-CNN技术,以便为所有对象生成对象建议object proposals。然后,采用Res-Net 提取基于区域和基于图像的特征。为了将自然语言问题转换为基本上设计用于视觉问题回答(VQA)的可执行程序,应用了语义解析模块 semantic parsing module。
Behind the Model
研究人员使用称为CLEVR的数据集来测试深度学习模型。这是一个诊断数据集,有助于解决视觉问题解答(VQA)。该模型通过课程学习 curriculum learning 来学习,即从简单场景中的简短问题中学习单个对象的表示形式或概念representations or concepts开始。这有助于模型学习基于对象的概念 object-based concepts ,例如颜色和形状。然后,模型通过利用这些基于对象的概念来学习关系概念 relational concepts,去解释 对象引用 object referrals.。
此外,该模型自然地学习了纠缠的视觉和语言概念,从而可以针对视觉场景和语义程序 visual scenes and semantic programs进行组合概括 combinatorial generalisation。在这种情况下,有四种形式的泛化,该模型首先泛化到比训练集中的场景具有更多对象和更长语义程序的场景。其次,模型推广到新的视觉属性组成visual attribute compositions。第三,它概括为能够快速适应新颖的视觉概念,最后,将学习到的视觉概念转移到诸如图像字幕检索之类的新任务上。
NS-CL包含以下三个模块:
- 基于神经的感知模块Neural-Based Perception Module:该模块通过从场景中提取对象级别的表示来工作
- 可视化语义分析器Visually-Grounded Semantic Parser:此模块用于将问题翻译为可执行程序
- 符号程序执行器Symbolic Program Executor:此模块读取对象的感知表示perceptual representation,对对象的属性或关系进行分类,然后执行程序以获得答案
NS-CL的优势:
- 这种深度学习模型以很高的准确率学习视觉概念。研究人员对所有物体属性的分类精度均达到近99
- 该模型允许在CLEVR数据集上进行数据高效的视觉推理。data-efficient visual reasoning
- NS_CL很好地泛化到新属性,新视觉外观以及新的领域特定语言。
- 该模型可以直接应用于视觉问题解答(VQA)。